Что такое веб-краулер? Все о поисковых роботах
Вы могли слышать термин «краулер» от веб-разработчиков, специалистов по сбору данных и SEO-экспертов. Я ежедневно сталкиваюсь с этим термином множество раз. В частности потому, что такие технологические гиганты, как Google и Bing, используют краулеры для индексации последних данных и отображения результатов запросов. Но недавно я задался вопросом: а как они, собственно, работают?
В этом посте я расскажу о веб-краулерах, принципах их работы, преимуществах, недостатках, типах и влиянии на поисковую оптимизацию (SEO).
Что такое краулер?

Веб-краулер (поисковый робот или “веб-паук”) – это автоматизированная программа, которая систематически ищет в интернете информацию о веб-сайтах и собирает огромные объёмы данных, как архивных, так и самых свежих. В частности, с его помощью можно индексировать сайты для поисковых систем, оценивать содержимое веб-сайтов и собирать огромные массивы данных для различных целей.
Преимущества
- Он лучше всего подходит для автоматизированного сбора данных, который позволяет экономить время и силы, получая большие объёмы информации, не требующей ручного вмешательства.
- Эти боты могут получить доступ и проиндексировать большое количество веб-страниц, что позволяет получить богатый и подробный набор данных для изучения.
- Регулярно работающий веб-краулер гарантирует, что данные будут включать самое свежее содержимое.
- Веб-пауки помогают оптимизировать сайты для поисковых систем, оценивая содержание и структуру (здесь я имею в виду улучшение видимости и ранжирования).
- Поисковые роботы следят за конкурирующими сайтами, предоставляя важную информацию об их стратегии, содержании и эффективности.
Недостатки
Теперь о недостатках технологии веб-краулинга, хотя, на мой взгляд, все они легко перевешиваются рядом преимуществ, которые она даёт, в частности, в сфере ИТ и технологий:
- Краулеры могут потреблять значительную пропускную способность и ресурсы сервера, что может замедлить работу сайтов, которые они просматривают, и увеличить операционные расходы оператора краулера.
- Для работы поисковых роботов требуется регулярное обслуживание и модернизация, поскольку они должны регулярно адаптироваться к изменениям в структуре и макете веб-сайтов, а это уже весьма трудоёмко и технически сложно.
Веб-краулинг – как это работает
Итак, вкратце, веб-краулинг – это компьютеризированная практика систематического сканирования интернета для индексации и сбора информации с вэб-сайтов. Если говорить более подробно, то у нас есть…
- Отправная точка
На этом этапе URL-адреса загружаются в очередь, которая управляет списком ссылок, которые будут посещены сайтом-краулером.
- Выборка
На этом этапе краулинга сайтов выполняются HTTP-запросы к URL-адресам, чтобы получить HTML-содержимое веб-страниц. Это позволяет поисковому роботу получить доступ к ним и оценить их структуру и содержание.
- Парсинг
Полученный HTML-контент анализируется для извлечения ссылок, которые затем добавляются в список URL-адресов для просмотра. Кроме того, из веб-страниц извлекаются необходимые данные, включая текст, фотографии и метаданные.
- Хранение
Собранные данные сохраняются в базе данных или индексе для простого поиска, дополнительных исследований и анализа.
- Последующие переходы по ссылкам
Веб-краулер продолжает переходить по ссылкам, обнаруженным на текущей вэб-странице, повторяя операции получения, разбора и сохранения для каждого нового URL.
- Ограничение скорости
Чтобы не перегружать сайты, поисковые роботы следуют директивам robots.txt и делают паузы между запросами.
Чтобы лучше понять, как это работает, советую вам посмотреть видео о том, как вообще работает поиск. Вот короткое видео, которое поможет вам понять принцип его работы:
4 типа веб-пауков
Веб-краулер поисковых систем
Он использует краулеры для сбора информации для страниц результатов поисковых систем (SERP), таких как Bing и Google. Он ориентирован на скорость и эффективность и способен обрабатывать большие объёмы данных о миллионах веб-страниц.
Вертикальный паук
Также известный как тематический или ориентированный краулер, он предназначен для сбора данных из определённых областей интересов или тем, таких как новостные сайты, научные работы или отраслевые сайты. Он оптимизирован для выявления и отслеживания ссылок, связанных с их областью интересов, игнорируя нерелевантный контент.
Дополнительный поисковый робот
Этот бот ориентирован на обновление уже существующих индексированных данных, а не на получение всех данных с нуля. Дополнительные краулеры эффективно поддерживают актуальные индексы, периодически посещая и обновляя только изменённые части сайтов.
Глубинный веб-краулер
Он предназначен для доступа и индексирования содержимого, недоступного для стандартной поисковой системы, например динамических страниц, баз данных и содержимого, скрытого за формами входа в систему. Глубинные веб-краулеры могут перемещаться по формам, использовать учётные данные для доступа к закрытым областям и анализировать динамический контент, созданный на JavaScript.
Примеры использования
Помнится, впервые я задумался о настройке поискового робота, когда занимался SEO-анализом, веб-архивированием и, чуть позже, тестированием безопасности. Но большинство моих коллег используют его для…
- Исследование рынка: В бизнес-целях вы можете использовать технологию краулинга для сбора информации о конкурентах, тенденциях рынка и предпочтениях клиентов.
- Сравнение цен: Если у вас есть сайт электронной коммерции, используйте поисковых роботов для отслеживания цен конкурентов и изменения собственной стратегии ценообразования.
- Агрегация контента: Агрегаторы новостей и сервисы кураторства контента используют краулеры для сбора статей, записей в блогах и другой информации из различных источников.
- Академическое исследование: Не стесняйтесь собирать данные из онлайн-источников, баз данных и форумов, если это необходимо.
- Индексирование в поисковых системах: Веб-пауки помогают поисковым системам индексировать вэб-страницы и предоставлять релевантные результаты поиска.
Как создать веб-краулер

Чтобы создать веб-краулер самому, вам понадобятся некоторые навыки кодирования. Если же вы хотите создать краулер, не прибегая к кодированию, то я рекомендую использовать специальные инструменты для создания ботов.
Итак, давайте разберёмся с этим шаг за шагом.
- Создайте среду разработки.
- Начните с выбора языка (в этой статье я привожу пример с Python).
- Установите такие библиотеки, как: requests – для выполнения HTTP-запросов; BeautifulSoup или lxml – для разбора HTML; а также Scrapy – для более комплексного фреймворка для просмотра сайтов.

- Создайте базовую структуру.
- Укажите URL-адрес (один или несколько), который нужно просмотреть.
- Для создания базовой структуры используйте библиотеку requests, чтобы получать содержимое веб-страниц с помощью HTTP-запросов.
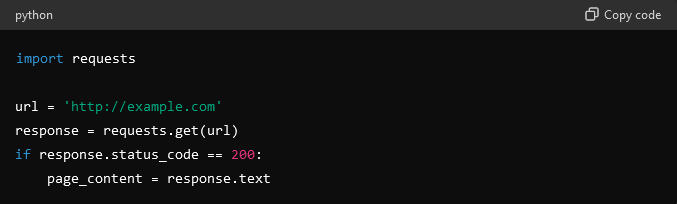
- Разберите содержимое HTML.
Как только вы получите контент, переходите к следующему шагу – разбору HTML для извлечения необходимой информации. Для этого можно использовать такие инструменты, как BeautifulSoup или lxml.
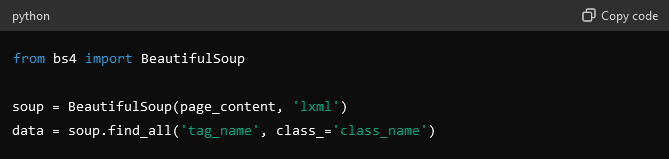
- Займитесь извлечением данных.
- На этом этапе вам нужно определить точки данных и указать, какие данные вам нужны, например заголовки, ссылки или изображения.
- Теперь извлекайте данные, используя HTML-теги и имена классов для поиска и извлечения данных.
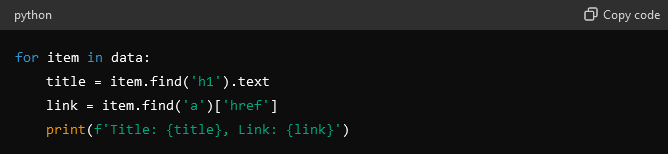
- Реализуйте логику поиска.
- Вам нужно будет использовать рекурсивную обработку и создать функции для перехода по ссылкам и просмотра дополнительных страниц.
- Определите и перейдите по ссылкам пагинации, чтобы продолжить беспрепятственный просмотр сайта.
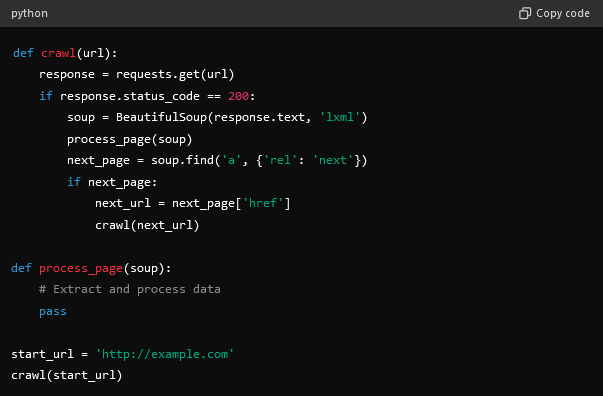
- Сохраните извлечённые данные.
- Для структурированного хранения данных используйте базу данных, например SQLite, MySQL или MongoDB.
- После этого необходимо сохранить данные в формате CSV или JSON.
- Обработка ошибок и исключений.
- Установите таймаут для HTTP-запросов, чтобы справиться с медленными ответами.
- Выполните повторное выполнение неудачных запросов.
- Соблюдайте robots.txt и ограничение скорости.
- Убедитесь, что ваш краулер ответственно воспринимает файл robots.txt целевого сайта.
- Вы также можете использовать задержки между запросами, чтобы не перегружать сервер и не влиять на его производительность.
Веб-краулинг и веб-скрейпинг: в чем разница?
Краулинг веб-сайтов подразумевает регулярное исследование интернета с целью индексации и обнаружения веб-страниц, как правило, для поисковых систем. Скрейпинг же – это получение конкретных данных с сайтов для анализа и применения в различных областях, таких как маркетинг, SEO, рекламные кампании и т. д.
| Аспект | Краулинг | Скрейпинг |
| Назначение | Индексирование и обнаружение веб-страниц | Извлечение определённых данных из веб-страниц |
| Пример использования | Потребности поисковых систем (в первую очередь) в создании или индексации страниц | Используется частными лицами и предприятиями для сбора данных для анализа |
| Процесс | Система, которая методично переходит по ссылкам, открывая новые страницы | Разбор и извлечение данных из идентифицированных веб-страниц |
| Инструменты | Googlebot, Bingbot и другие боты поисковых систем | BeautifulSoup, Scrapy, Selenium |
| Результат | Полный указатель веб-страниц | CSV, JSON или базы данных |
| Сложность | Как правило, более сложные процессы, требующие обработки больших объёмов данных | Может быть проще, но сложность возрастает при использовании динамического контента |
Как краулеры влияют на SEO?
Как я уже говорил, веб-пауки играют важную роль в поисковой оптимизации (SEO), индексируя сайты, что, в свою очередь, напрямую влияет на их отображение в результатах поиска.
Когда поисковый робот исследует сайт, он оценивает его содержание, структуру и ключевые слова, чтобы определить релевантность и рейтинг. Эффективные SEO-стратегии, такие как оптимизация скорости страницы, использование соответствующих тегов и создание высококачественного контента, помогают краулерам эффективно индексировать сайт и, как следствие, повышать его видимость.
Однако если вы допускаете ошибки и дублируете материалы, используете неработающие ссылки или заблокированные ресурсы, будьте готовы к тому, что это может помешать краулеру эффективно индексировать сайт, снижая его рейтинг в поисковых системах.
Этические аспекты краулинга
Веб-краулинг требует соблюдения определённых правил и этических норм для обеспечения законности и уважения к ресурсам других сайтов. Прежде всего, важно следовать указаниям, представленным в файле `robots.txt`, который размещается на сайтах и указывает, какие страницы можно или нельзя индексировать краулерам. Кроме того, необходимо учитывать условия использования сайта, так как некоторые ресурсы запрещают автоматизированный сбор данных или устанавливают определённые ограничения.
Ограничение частоты запросов — ещё один важный аспект. Избегайте отправки большого количества запросов за короткий промежуток времени, чтобы не перегружать серверы. Я рекомендую устанавливать разумные интервалы между запросами. Если сайт предоставляет официальный API, лучше использовать его для сбора данных, поскольку это обычно более этично и удобно. API часто имеет встроенные ограничения на запросы и предоставляет структурированные данные.
Этические аспекты вэб-краулинга также имеют большое значение. Необходимо уважать конфиденциальность пользователей и избегать сбора личных данных без их разрешения. Следует минимизировать воздействие на серверы сайтов, используя кэширование данных и оптимизируя частоту запросов. Важно также уважать права интеллектуальной собственности, не нарушать авторские права и не копировать данные таким образом, который может нарушить эти права.
При использовании собранных данных также важно придерживаться этических норм. Используйте информацию ответственно и только для законных целей, избегая её продажи или распространения без разрешения владельцев данных. Если возможно, уведомляйте владельцев сайтов о намерении собирать данные и получайте их согласие. Соблюдение этих правил и норм поможет избежать юридических проблем и обеспечит уважительное отношение к ресурсам других.
Тенденции будущего
Вы же все уже знаете об ИИ и МО, так ведь? На мой взгляд, достижения в области искусственного интеллекта (ИИ) и машинного обучения (МО) определят будущее краулинга веб-сайтов. Я предполагаю, что краулеры на базе ИИ станут более интеллектуальными, смогут распознавать контекст и извлекать более релевантную информацию. Кроме того, я считаю, что рост голосового поиска и индексации по принципу mobile-first повлияет на то, как поисковые роботы будут ранжировать и индексировать материалы.
Кроме того, растущее внимание к конфиденциальности и безопасности данных пользователей должно заставить создавать краулеры-пауки, которые придерживаются более строгих законодательных рамок, гарантирующих этичность и ответственность при сборе данных.
Заключительные размышления
Технология веб-краулинга имеет решающее значение для цифровой экосистемы, влияя на SEO, маркетинговые исследования и агрегацию контента. Чтобы избежать проблем с законом и обеспечить ответственное получение данных, я настоятельно рекомендую вам следовать этическим процедурам и соблюдать политику краулинга. И будьте готовы к будущим достижениям в области искусственного интеллекта и машинного обучения, которые сделают веб-краулеры более эффективными и контекстно-ориентированными.
ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ
Это процесс, в ходе которого автоматизированные программы систематически просматривают интернет, индексируют содержимое сайтов, собирают данные для обновления индексов поисковых систем и обеспечивают эффективное извлечение информации при поиске.
Они просматривают веб-страницы, получая и анализируя HTML, собирают и индексируют данные, чтобы собрать информацию для различных целей.
Краулеры индексируют вэб-страницы, позволяя поисковым системам предоставлять пользователям актуальные и свежие результаты поиска.
Нет, они различаются по алгоритмам, масштабу и направленности в зависимости от конкретных целей и реализации.
Бесплатные краулеры (особенно!) сталкиваются с такими проблемами, как ограничение скорости, CAPTCHA, динамический контент и соответствие файлам robots.txt.
Они влияют на SEO, индексируя содержимое сайта, что сказывается на видимости и рейтинге на страницах результатов поисковых систем.
Нет, вэб-краулеры ограничиваются файлами robots.txt и могут быть заблокированы от доступа к определённым частям сайта.
Основное различие между краулингом и скрейпингом заключается в том, что краулинг индексирует целые страницы, а скрейпинг извлекает конкретные данные с определённых сайтов.
Веб-сайты используют файлы robots.txt и мета-теги, чтобы указать, какие страницы и с какой периодичностью могут посещать вэб-пауки.