How to Scrape Images From a Website: Best Tools, Practices, and Tips for 2025
Many product owners need image scraping for listing management or product research. Sometimes this task requires collecting thousands of images from various websites. Obviously, downloading them manually is not a solution. Tools allowing downloading all images don’t make things much better: they collect all image files, including irrelevant site logos and thumbnails.
The only way to make web scraping of images quick and convenient is to use special scraping tools. However, it implies another challenge on your way: anti-scraping tools installed at almost any website. A hint: it will require dealing with a proxy website. So, how to deal with restrictions, collect data quickly, and, after all, make things as simple as possible? Let’s straighten it out.
How does scraping pictures work
In a nutshell, scraping pictures implies pulling an image URL from a website. For instance, if you need a pool of images from a Google search, you would need to visit every image source and download them. Instead, you can scrape Google images and automate the process.
When you need to have an image link from a particular source, you need to open the HTML code of the website and copy the link from it — like here:

When you scrape images, you automate this task and get images from a website much quicker.
Image Scraping Tools
The easiest way to parse data, including images from websites, is to opt for a ready images scraping solution. There are plenty of free and paid tools that require minimum technical skills. However, they either require a monthly fee or have particular limits — in other words, they are not so universal.
As an alternative, you can use Python libraries and tools to scrape png images (or other formats) from websites. Although it might seem not so straightforward as just clicking a couple of buttons in a ready tool, Python is considered one of the top popular and convenient options for parsing data. It can scrape almost anything you need, unlike the ready solutions that don’t imply programming skills. Let’s dive in deeper to see how to deal with both options.
How to scrape images from websites with ready-made tools
The main challenge here is to select the best suitable one: they can all differ by purpose. Here are the top popular image scrapers:
Scraping Bot

This tool allows you to select the best suitable API for a particular sector. The tool is very convenient for scraping images and other data for eCommerce. You can select from various plans, including a free one: it allows you to create five concurrent requests, perform JS Rendering (Headless Chrome), and use Premium Proxies.
ScrapeWorks
ScrapeWorks offers customized solutions for large enterprises in various industries. Using its tools, you can scrape images from various websites and save it in any format you need: JSON, Excel, XML, CSV and more. It suits different industries and is especially good for eCommerce, real estate, healthcare, and automobiles. The protection methods accurately work with target websites and carefully overcome the limitations. ScrapeWorks doesn’t publish its pricing plans and works on request.
ScraperAPI
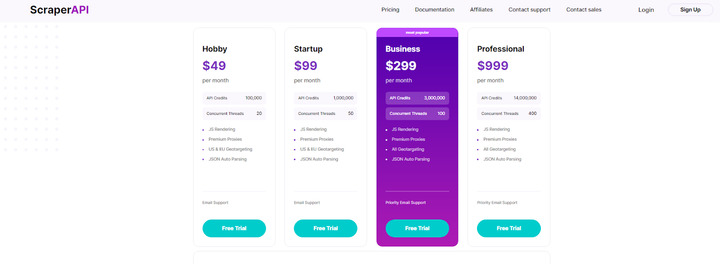
Scraper API is an out-of-the-box tool that automates the whole process, and uses top-tier proxies, and anti-bot detection. It allows you to choose from multiple settings, including IP geos. To start using it, you need to share the URL of the site you need to scrape with the API key. You will find very detailed instructions on how to install ScraperAPI and customize it if needed.
ParseHub
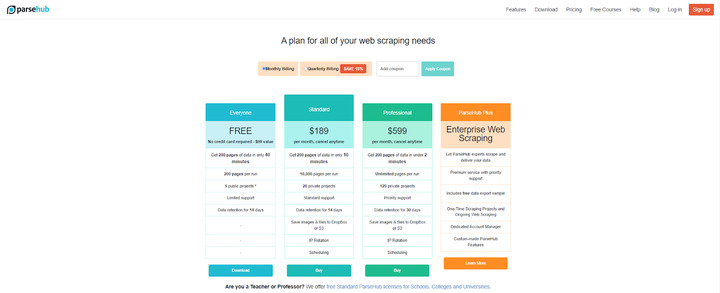
ParseHub is one of the easiest tools for novices. It doesn’t involve any complicated settings and allows you to parse images just by clicking on them. Pricing plans vary depending on what you need. For instance, a free version allows you to get data from up to 200 pages within 40 minutes and create five public projects. There are also $189 and $599 monthly plans, plus an enterprise solution at a specific price on request.
How to scrape images from websites with Python
When you need more features than ready-made tools can offer, programmed scraping comes to the rescue. It’s pretty easy for people who know Python well, but won’t be so for beginners. To scrape with Python (get image from URL, just like with previous tools), you need to have particular skills and knowledge.
Besides, there are many methods of how to scrape images from a website with Python: you can use various libraries, scripts, and tools. Here are the most popular ones:
- BeautifulSoup and lxml libraries. Work best for parsing HTML and XML
- Scrapy framework. A free framework specially created for web crawling and extracting data from websites — including web scraping images.
In this review, we will show one of the most popular and simple scraping methods using the BeautifulSoup library. Here is a step-by-step tutorial:
Step 1. Import the required libraries:
from bs4 import BeautifulSoup
import requests
Step 2. Create a request so that Beautiful Soup could parse the required page:
html_page = requests.get(‘http://yoursite.com/’)
soup = BeautifulSoup(html_page.content, ‘html.parser’
warning = soup.find(‘div’, class_=”alert alert-warning”)
book_container = warning.nextSibling.nextSibling
Step 3. Indicate the images tag to extract only pictures:
images = book_container.findAll(‘img’)
example = images[0]
example
Step 4. As the result, you get the image URL looking like this:
<img alt=”A Light in the Attic” class=”thumbnail” src=”media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg”/>
Step 5. Pull out the URL:
example.attrs[‘src’]
You will get the following output:
‘media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg’
Step 6. Use Shutil package for Python to download an image from url requests:
url_base = “http://yoursite.com/” #Original website
url_ext = example.attrs[‘src’]
full_url = url_base + url_ext
r = requests.get(full_url, stream=True)
if r.status_code == 200: #200 status code = OK
with open(“images/book1.jpg”, ‘wb’) as f:
r.raw.decode_content = True
shutil.copyfileobj(r.raw, f)
Step 7. Create image previews to see that you downloaded what you needed. It will require importing two extra packages called matplotlib.pyplot and matplotlib.image:
import matplotlib.pyplot as plt
import matplotlib.image as mpim
The code for image previews will look the following:
img = mpimg.imread(‘images/book1.jpg’)
imgplot = plt.imshow(img)
plt.show()
As a result, you will see the image you extracted. Note, that this method will allow you to extract only static pages, and you will need more sophisticated methods to work with interactive sites. Overall, you can create any customized Python image scraper using its tools and your programming skills.
Why do you need proxies for scraping
Web scraping of an image or any other content is always associated with proxies. Why so? In fact, scraping is not a thing that a website owner would welcome. Who would want to provide a competitor with the full data for their marketing research? This is why most websites, especially in the eCommerce industry, are highly protected from web scraping.
So, when you run your scraping bots, it may result in failure: the site’s protection will block your tools and won’t allow you to scrape any content. The only way out is to use proxies for scraping that can hide your activity and painlessly pull out images, prices, and other information you need for your marketing research.
- A proxy will help manage geo-restrictions. If the site’s content is not available in your region, you can change your geo via a proxy.
- A proxy can hide your IP. When you make too many requests from a site from your IP, the site can block you due to request limitations. A proxy for scraping hides your IP and performs as many requests as you need for efficient scraping.
You can use proxies for image scraping when you work with ready tools, and also when you write scripts for Python.
A tip: be careful with a proxy website you are using. A free proxy website doesn’t always offer proxies for scraping that perform as you wish them to, so ProxyBros recommend using high-quality paid options. Try to choose a reliable proxy website, with positive reviews and moderate prices. Besides, make sure a proxy website offers some extra options, like moneyback for non-working proxies.
To sum up
Web scraping might be challenging, especially when you scrape png and jpg files. Still, if you use the right tools and know the ins and outs of non-programming and programmed scraping, it makes your life much easier. The mixture of the right web scraper and a top-tier proxy will ensure seamless and efficient work.