Instagram Scraping: 3 Best Ways to Gather Data from Instagram

Modern technological advancements have provided businesses with endless resources to boost their corporate growth and achieve operational efficiency. Social media is one of those resources that enable companies to engage with their target audiences and convert leads into loyal customers. Social networking sites like Facebook, Instagram, and Twitter generate huge amounts of data that can be used for research and marketing purposes.
Being the 4th most used social media platform with more than 2.9 monthly users, Instagram is the preferred choice of marketers for branding, promotion, and targeting. The world’s leading marketing agencies use Instagram scraping to automatically collect publicly-available data of Instagram users to analyze consumer behavior. The technique provides valuable insights such as customers’ contact info, images, likes, profiles, followers, comments, locations, and hashtags. There are several methods to scrape Instagram users’ data such as manual extraction and scraping tools. However, these methods are time-consuming and have certain limitations.
Hence, this article presents the 3 best Instagram scraping techniques to gather users’ data from Instagram and get better marketing results. So, let’s dive in!
What Data Can You Collect by Scraping Instagram?
Publically-available data on Instagram is of different types such as user profiles, hashtags, posts, comments, locations, URLs, bio details of followers, and the number of likes per post.
Let’s discuss these categories one by one.
- Data from the User Profiles
Scraping data from user profiles on Instagram is very easy. Use the internal API endpoint to retrieve details for the first 12 posts. However, you can use another endpoint to scrape data from all user posts on Instagram.
- Posts and Users
To find posts with specific hashtags, use /explore/tags endpoint. Besides, use the GraphQl service of Instagram rather than scraping the HTML endpoint. The GraphQl endpoint searches for the hashtag-marked posts based on the page size, tag name, and offset. You can also find users from these Instagram posts. Similarly, use /explore/locations REST endpoint to search for Instagram posts by location. This way, you can find a large number of posts tagged with a specific location.
- Comments
Each Instagram post has different comments posted by users. You can tap the Load more comments button to view all comments on a post. For automation, use the page.click()function of Puppeteer and scrape all comments from the Instagram post.
- Bio Details of Followers
The bio details of followers play a key role in social media marketing. Companies can use this data to target potential buyers in various niches and expand their consumer base. That is why several tools are available online for scraping Instagram followers and retrieving their bio details.
- Email and Phone Data
Instagram scraping allows users to gather emails and phone numbers of Instagram users and use this data for targeted email and phone marketing. However, you need specialized tools like Instagram email scraper and Instagram phone number extractor to collect this type of information as analyzing individual Instagram accounts and scraping their contact details is a time-consuming task.
Scraping Instagram Data: How Does It Work?
What is Instagram Scraping?
Instagram web scraping is a technique used by digital marketers and influencers to gather Instagram users’ data automatically. Since Instagram’s terms of use prohibit the use of any kind of scrapers or crawlers, its advanced anti-bot system restricts automation bots and traffic from accessing this platform. The official Instagram API python does not allow third-party Instagram scrapers to pull data without users’ consent and use it for research and marketing.
How to Scrape Instagram?
Despite these restrictions, companies use different types of Instagram scrapers to scrape Instagram followers, photos, comments, hashtags, user profiles, and much more. The best way to web-scrape Instagram is to use Instagram scraper bots, which deeply analyze different profiles and collect the type of data they’re programmed to gather. Marketers can download the final report in the form of a document, webpage, or database and use this information to target the right people. Automation bots have made the data-gathering process very convenient, fast, and more efficient.
The use of an API (Application Programming Interface) in the Instagram web scraping process delivers much better results. An API connects disparate pieces of software and offers data-driven insights for informed decision-making. Web scraping API enables companies to scrape Instagram users’ data in real time, build an automated data collection funnel, and automate the Instagram scraping process. Besides, APIs eliminate human intervention and directly send the findings to the database.
Connecting the Instagram scraping tool to an API enables marketers to directly communicate with Instagram and send automated scraping requests to gather users’ data at regular intervals. By automating the process of scraping Instagram followers, the system keeps scraping Instagram without any interruption. This saves marketers precious time and allows them to get valuable insights while focusing on their most critical tasks.
Is Instagram Scraping Legal?
Yes, it is legal to scrape publically-available data and there are no legal repercussions for web scraping Instagram. Businesses can collect data from public profiles without seeking permission. However, scraping confidential or copyright-protected information is strictly prohibited. Hence, be careful while using Instagram email scraper or similar tools, and make sure your output for data does not violate the CCPA or GDPR.
3 Ways to Scrape Instagram
Explore below the 3 most reliable and tried & tested ways to scrape Instagram:
1. Python
Instagram scraping using Python is probably the easiest method of all. You just need to put the Instagram URL to your python code, run the program, and store your specific data points in a data frame.
Python offers great web scraping packages like Selenium, Instaloader, Beautiful Soup, etc. Let’s learn how to use Instagram scraper python by using Selenium:
- Install Python with Selenium web scraping package on your device
- Open the Instagram site and identify the data points you need such as followers, posts, and the number of users following
- It’s time to develop the code to scrape Instagram. Start by importing the Selenium package, a web driver manager, and the pandas package

- Now, install the driver being used by the web browser

- Declare the variables that define the type of data you want to scrape from Instagram. For instance, if you choose posts, hashtags, and followers, the driver.get function will retrieve their text
- Next, use the driver.find_element_by_xpath() function to save the text retrieved from the website inside your declared variables

- To get the full XPath, open an Instagram page, right-click on any post, tap inspect > look on the inspector console, and copy the full XPath
- Copy-paste the full XPath in your corresponding variable. Repeat the same process for other variables too

- Print out your declared variables as your program runs
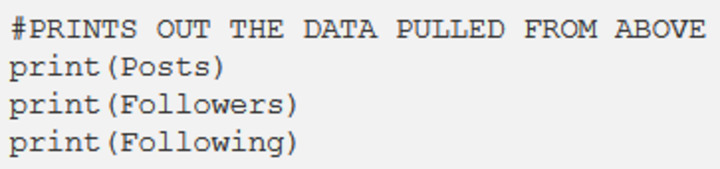
- Create an empty Pandas data frame containing your chosen variables and append that data frame to ours

- Finally, run the program line-by-line or use the .py file in your command prompt. A pop-up will be shown on your Chrome browser. Open your desired Instagram account page and print out posts, followers, user profiles, images, and much more on your Python console.
With python Instagram scraper, you can scrape comments, user stories, posts, profiles, geotags, and hashtags. This method also allows users to download videos and pictures from Instagram profiles, customize their filters, and detect profile name changes. However, the process is a bit complicated and requires good command of Python for successful execution.
2. Using a Scraping Bot

Another convenient way to collect publicly-available data from Instagram is by using the Scraping Bot Instagram scraper. You can gather users’ Instagram profiles, posts, photos, videos, comments, hashtags, followers, and likes in JSON format.
Here’s how Scraping Bots work:
- First of all, create a new account on Scraping Bot to get free access to 100 monthly credits. Click on Register or Free Plan and enter your basic details to get started without providing any payment information.
- Now, log in to your account and enter the Data Scraper API section under Documentation.
- Set up the endpoint with two API calls that will help you scrape Instagram data without getting blocked.
- To set up the endpoint, get the ResponseID first by entering the required parameters and running a first API call.
- Now you can configure a GET request for response. Complete the response endpoint by inserting the ResponseID and filling the scraping parameters previously used for the POST API call.
- Next, execute the API call and see if the scraping is ready to use.
- Your web scraping setup is now complete. Start gathering Instagram data.
Instagram web scraping through Scraping Bot is a fast and efficient method that allows users to extract huge amounts of data cost-efficiently. The technique is easy to use, delivers structured data, and offers robust performance. At the same time, Scraping Bot has a steep learning curve and takes time before you can get your desired results. Moreover, even minor mistakes in code writing or execution can get the scraper blocked.
3. Using a Scraping Proxy

Although several Instagram data scraping proxies are available on the internet, we recommend you build your own proxy to get more control.
Here’s how you can do this:
- Download and install CCProxy on your computer
- Connect your computer/laptop with a mobile hotspot. Make sure you have only 1 internet source
- Go to your CCProxy account and create a new Wizard to fetch the default code or manually configure the IP
- Tick the IP address and tap retrieve to access the default adapter IP. Press the OK button to get a proxy on the -001 username
- You can now use this new proxy across various places within your operating system
- Press the Start button to enable your proxy
- Now, it’s time to start scraping. Open the program settings and set the scrape results limit to 7000
- Adjust the delay limit between scrape segment/fetch to 8-10 seconds
- Check the first Instagram account, tap the Follower Scrapper, and insert the target username in the new window. Besides, set sleep values as 1 and 1 and press start
- The proxy will automatically scrape 7000 results and record them in a LOG file
- Finally, export the scraped Instagram data to a new file. Repeat the whole process for more accounts
Scraping proxies are cost-effective, robust, and secure as they are rarely blocked by sites. Their location keeps varying with time which ensures a high success rate. However, they can be detected easily when on the same subnet and have limited applications.
What Should I Choose to Scrape Instagram?
Both Python and Scraping Bot are popular methods for Instagram data scraping. You can observe Instagram user behaviors, create a database of potential buyers, and get valuable insights into your customers’ product interests.
However, the strong anti-bot system of Instagram makes these two scraping methods less efficient. To solve this challenge, use an Instagram scraping proxy that hides your original IP and allows you to retrieve your required data without getting blocked.
A reliable scraping proxy offers exclusive benefits such as:
- Prevents your IP address from getting blacklisted
- Extends the number of requests Instagram scrapers can be made in a given duration
- Allows you to send scraping requests from different geographical locations
Frequently Asked Questions (FAQs)
Choose an Instagram web scraper, insert the profile link of the target account in the search query, run the scrapper, and wait for a few minutes until the tool downloads your data.
An Instagram profile scraper is a python-based command-line application that allows its users to scrape photos, videos, posts, comments, and similar data from an Instagram user’s profile.
Yes, you can scrape publically-available data from Instagram without seeking users’ permission unless it is the confidential information or intellectual property.
To scrape images from Instagram, import the module, pass requests instance into URL and a Beautifulsoup() function, and use the ‘img’ tag to find all images.
To scrape users’ data by using python Instagram API, create an Instagram Developer Account, generate an access token, and call the Instagram API with RapidAPI.
Scraping proxies are the safest because they hide your IP and help you scrape data from Instagram without getting blocked.
Final Words
Instagram scraping plays a key role in marketing research, branding, and promotion. Renowned businesses scrape data of Instagram users to analyze their customers’ behaviors, make data-driven decisions, and achieve corporate efficiency.
However, scraping Instagram data manually is very time-consuming and prone to error. Instead, marketers use automated scraping tools to retrieve key details about user profiles, followers, comments, likes, hashtags, etc. You can scrape data from Instagram with Python, Scraping Bot, or scraping proxies.