The World of Metadata: Definition and Operational Insights

Have you ever wondered how the vast digital universe stays so impeccably organized? How do files, photos, and documents seem to have a life of their own, knowing where to be and how to behave? The answer lies in metadata. At its core, it relates to the set of descriptors that provide context to data. It’s not the main content but rather the tags, labels, and notes that tell systems more about that content.
As our online ecosystems grow exponentially, the sheer volume of data can be overwhelming. Metadata ensures that info isn’t just a jumbled mess. It aids search engines in delivering accurate results, helps software applications sort and manage files, and even guarantees that your social media feeds show you content tailored to your preferences. So, whether you’re a tech enthusiast or just curious about the inner workings of the online world, strap in for a deep guide.
Metadata Unveiled: Beyond the Basic Definition
At its simplest, this term is often described as “data about data.” While this definition is accurate, it barely scratches the surface of its profound significance. Imagine being handed a beautifully wrapped gift. The gift is the data, but the metadata is the tag that tells you who it’s from and perhaps a hint about its contents. In other words, it’s the context, the backstory, and the additional layer of information that enriches our understanding of the primary data.
Besides, it’s not just a static label; it’s a dynamic entity that evolves, adapts, and provides invaluable insights. For instance, when you snap a photo with your smartphone, the image is the data. But the date it was taken, the location, the camera settings — all these additional details form the meta-info. This information lets you search for photos taken on a specific date or location.
Types of Metadata
Overall, it is a broad concept with numeric characteristics and purposes. Let’s delve into the primary types of metadata that play pivotal roles in our digital interactions: descriptive, structural, and administrative.
Descriptive
This type is more like a “publicist” of the info world. Its main job is to provide information that helps in discovery and identification. Whether it’s a book’s title, the research paper’s author, or the keywords associated with a digital image, descriptive info type makes information discoverable and accessible. The set of details ensures you find what you’re looking for when searching for a specific piece of information.
Structural
If descriptive metadata is the publicist, structural type is the architect. It’s concerned with how different pieces of info relate to one another. Think of a multi-chapter eBook. This type would provide information about the chapters’ order, the sections’ hierarchy, and the relationship between text and accompanying images. It ensures content is organized and presented in a logical, coherent manner. Understanding and effectively implementing structural information can be the difference between a well-organized database and a chaotic jumble of information.
Administrative
Here things get a bit technical. The administrative type is like the backstage manager, ensuring everything runs smoothly behind the scenes. It deals with the more technical aspects of data management, such as when and how the info was created, the tools used, rights management, and preservation of information. For instance, if you’ve ever wondered about the copyright status of a digital image or the software used to create a document, you’re delving into administrative info. It’s crucial to robust administrative information, especially in contexts where info preservation, rights management, and technical specifications are paramount.
Technical
Technical metadata provides insights into digital resources’ quality, format, and characteristics. It might include file type, compression algorithms, resolution, and dimensions. For digital audio or video files, info of this type could encompass bit, frame, and sampling rates. This type is crucial for ensuring that digital content is accessible and rendered correctly across various platforms and devices.
Rights
Rights meta-information revolves around intellectual property, detailing a digital resource’s legal rights and restrictions. It can specify who holds the copyright, the duration of copyright protection, licensing terms, and any usage restrictions. In an era where intellectual property rights are paramount, rights info plays a crucial role in safeguarding creators’ interests and guiding users on permissible uses.
Preservation
Preservation metadata is the guardian of digital longevity. It captures information necessary to maintain and prolong the life of digital resources. It includes details about the digital resource’s origin, changes made over time, authenticity checks, and storage conditions. Preservation type ensures that digital content remains accessible, usable, and authentic over extended periods, safeguarding against data degradation or obsolescence.
Operational Insights: How Metadata Works
The operational significance of meta-information spans various digital platforms and tools, enhancing user experience and info retrieval. Let’s delve deeper into its applications and understand its pivotal role.
In Web Pages and Documents
Web pages and documents are embedded with metadata that provides essential information about their content and structure. For web pages, this information offers details such as the page’s author, creation date, and specific keywords, aiding in content categorization and presentation. On the other hand, documents containing this information can include the author’s name, number of revisions, and the document’s format. It ensures that software applications can present the document appropriately to the end-user.
In Search Engines
When users input a search query, search engines analyze the visible content and the associated meta-information to determine the page’s relevance. It ensures precision in search results, with search engines utilizing the meta information to index content accurately, rank web pages based on relevance, and display content that aligns with user queries.
In Digital Libraries and Archives
Digital repositories, such as libraries and archives, rely heavily on meta information for content management. This information aids in classifying and cataloging diverse content types, from documents to multimedia. It ensures content is systematically arranged, making it easier for users to navigate vast collections. Furthermore, users can search and filter results based on criteria, streamlining content access.
In Photography
Every digital photo is embedded with metadata, including details like aperture, shutter speed, ISO settings, and even the camera model. This information not only helps photographers understand the conditions under which a photo was taken but also aids viewers and other professionals in appreciating the technical aspects of the image.
In E-commerce Platforms
E-commerce platforms are bustling digital marketplaces, and meta-information here ensures that products are easily searchable and categorized. Each product listing is accompanied by information encompassing product specifications, reviews, ratings, and even supplier information. It enhances search algorithms and recommendation systems, ensuring customers find products that best match their preferences and needs.
Common Mistakes and Best Practices
Like with any tool, the effectiveness of info hinges on how adeptly it’s wielded. Missteps using this information can lead to inefficiencies, inaccuracies, and missed opportunities. Let’s explore common pitfalls and best practices to ensure your game is top-notch.
Mistakes to Avoid
As we delve into the common pitfalls, it’s essential to highlight the nuances that can make or break effective management.
- Overgeneralization: One of the most frequent mistakes is using overly broad or generic meta tags. While it might seem like a time-saver initially, it can lead to poor search results and info misclassification.
- Inconsistency: Using different terms or formats for similar info can create confusion. For instance, labeling one document as “Report_2025” and another as “2025_Report” might seem trivial, but it can complicate info retrieval.
- Neglecting Updates: Information isn’t static. You should update meta info as it evolves or its context changes. Failing to do so can render it obsolete or misleading.
- Overcomplication: While detailed information is valuable, there’s a fine line between thorough and overwhelming. Avoid adding excessive tags or categories that don’t offer significant value.
Tips for Effective Metadata Management
Harnessing the full potential of information requires a strategic approach. So, let’s set the stage with some foundational principles that underpin effective management.
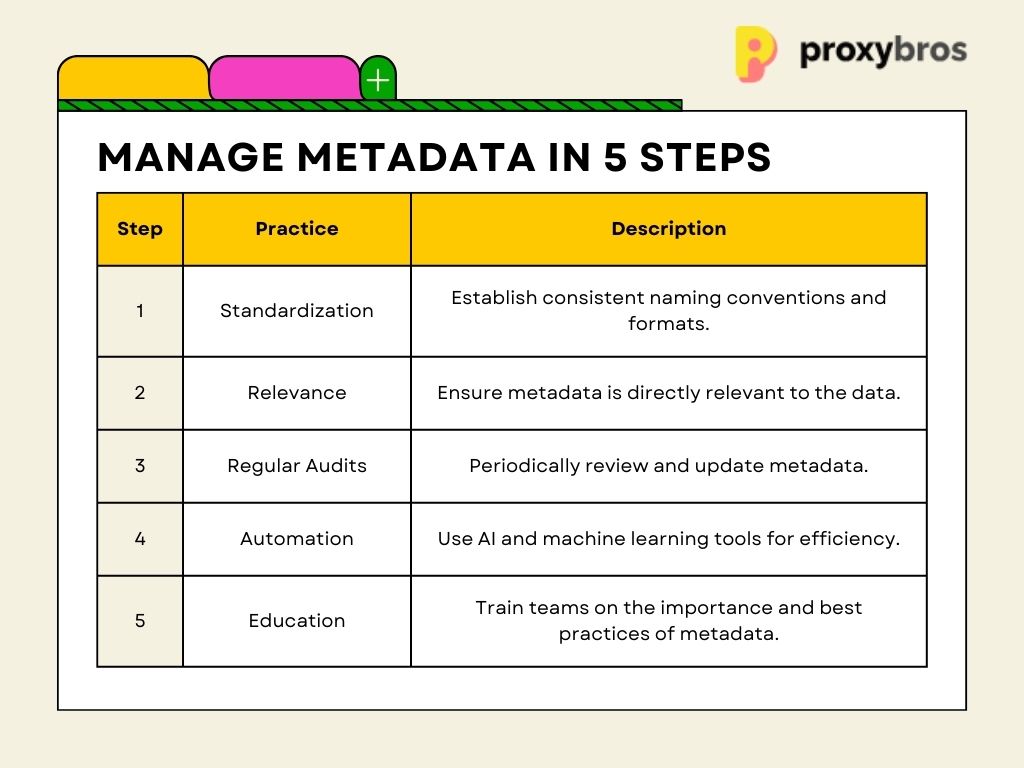
- Standardization is Key: Establish a consistent naming convention and format. It not only aids in information retrieval but also ensures that everyone on the team is on the same page.
- Prioritize Relevance: Ensure your meta info is directly relevant to the info it describes. It’s about quality, not quantity.
- Regular Audits: Periodically review and update your information. It ensures it remains accurate, relevant, and aligned with your data’s context.
- Leverage Automation: With advancements in AI and machine learning, there are tools available that can automate metadata generation and updates, ensuring accuracy and saving time.
- Educate and Train: Ensure that everyone involved in info management understands its importance and is trained in best practices. A unified approach can significantly enhance meta-info’s effectiveness.
Navigating the Metamorphosis: Top 5 Trends of 2025
As we sail through 2025, the world of information is undergoing transformative shifts. Let’s get to know the top five trends reshaping the metadata landscape.
1. The Modern Data Stack Revolution
This tool gained traction around 2016. It was designed to aid businesses in storing, managing, and utilizing information. This stack is characterized by:
- Self-service: Catering to a diverse user base.
- Agile Data Management: Swift and adaptive handling of data.
- Cloud-centric Approach: Prioritizing cloud-first and cloud-native solutions.
Tools like Fivetran, Snowflake, and Cloudflare’s data optimization and security services have revolutionized how we approach data. While Fivetran and Snowflake enable users to establish a data warehouse in minutes, Cloudflare ensures that data transactions are fast, secure, and efficient across the web. However, the traditional concept of metadata, which often involves passive inventories, is becoming obsolete in this dynamic ecosystem. With the rise of these modern tools, the demand for a more efficient meta-info handling system that can keep pace with real-time operations, like those facilitated by Cloudflare, is palpable.
By the way, if you’re searching for a comprehensive information hub, don’t hesitate to peruse this article about data warehouses, where you will find everything — from the definition to encompassing their components and advantages.
2. The Diverse Humans of Data
Gone are the days when only the IT department grappled with data. Today, data teams are a mosaic of roles, including data engineers, analysts, analytics engineers, and more. Each individual brings their unique “data DNA” to the table, employing various tools from SQL and Looker to Python and Tableau. This diversity, while a strength, also presents challenges in collaboration. Metadata is emerging as the glue that binds this diverse set of tools and people, providing the much-needed context in our expanding info ecosystem.
3. Rethinking Data Governance
Traditionally, data governance was often viewed as a bureaucratic hurdle. However, old-school governance methods are becoming impediments, with the modern data stack simplifying info ingestion and transformation. The narrative shifts from top-down enforcement to a bottom-up realization of its importance. Modern info governance is now seen as a collaborative effort, focusing on empowering data teams rather than just controlling them. This new approach necessitates a fresh meta-info management platform, emphasizing crowdsourcing context and automating data classification.
4. The Emergence of the Metadata Lake
Drawing parallels with the data lake’s inception in 2005, the metadata lake is the next big thing in 2025. As meta-info volume grows, so do its potential applications. The metadata lake serves as a unified repository, storing diverse information forms ready to be shared with other tools in the data stack. It simplifies the current use of metadata and paves the way for future applications, making the most of today’s deluge.
5. The Dawn of Active Metadata
2021 marked a significant shift when Gartner transitioned from its Magic Quadrant for Metadata Management to the Market Guide for Active Metadata Management. It signaled the end of passive management. Active platforms are:
- Always-on: Continuously collecting information without human intervention.
- Intelligence-driven: Processing metadata to derive insights, like auto-generating lineage from query logs.
- Action-oriented: Proactively driving recommendations and alerts in real-time.
Such platforms consolidate metadata and employ “reverse metadata” to integrate it into daily workflows.
Final Thoughts
Metadata is far more than just “data about data.” It drives our digital interactions, ensuring accuracy, relevance, and efficiency in the vast digital universe. Its role is rapidly evolving, adapting to modern data infrastructures, promoting collaboration among diverse data professionals, and setting new standards in governance. As we navigate this digital transformation era, businesses and individuals must harness the power of meta-info. Embracing its capabilities will enhance our current digital endeavors and lay the foundation for a more organized and insightful digital future.