What is a Web Crawler?
You may have heard the term ‘crawler’ from web developers, data scrapers, and SEO experts. I come across this term a lot of times daily. Tech giants like Google and Bing use crawlers to index the latest data and display query results. But how do they work?
In this post, I’m going to explore web crawlers, their working principles, advantages, disadvantages, types, and impact on search engine optimization (SEO).
What is Crawler?

A web crawler, often known as a spider or bot, is an automated program that systematically searches the internet for information on websites and gathers huge amounts of data, whether archived or the latest. Specifically, you may use it to index sites for search engines, evaluate website content, and collect massive datasets for a variety of purposes.
Advantages
- It is best for automated data collection, which saves time and effort by acquiring large amounts of information without requiring manual involvement.
- They can access and index a large number of web pages, resulting in a rich and detailed dataset for study.
- A web crawler online that runs regularly ensures data has the most recent content.
- Crawlers help optimize websites for search engines by assessing content and structure – I’m talking better visibility and ranking.
- Crawlers monitor competing websites, providing vital information about their strategy, content, and performance.
Disadvantages
Below, I will list several drawbacks of web crawling technology, although, to my mind, they are all pretty outweighed by the number of benefits it brings to the IT field.
- Crawlers can consume significant bandwidth and server resources, potentially slowing down the websites they scrape and increasing operational costs for the crawler operator.
- Crawlers require regular maintenance and upgrades to function since they must adapt to changes in website structures and layouts, which makes the process time-consuming and technically challenging.
Web Crawling – How it Works
So, in short, web crawling is the computerized practice of systematically scanning the internet to index and collect information from websites. Whereas, in more detail, we’ve got…
- Starting Point
At this stage, URLs are loaded into a queue, which manages the list of links that a URL crawler website will visit.
- Fetching
At this step of site spidering, HTTP queries are made to URLs to acquire the HTML content of the webpages. This allows the crawler website to access and evaluate the structure and content of web pages.
- Parsing
The retrieved HTML content is parsed to extract links, which are then added to the list of URLs to crawl. Furthermore, pertinent data from web pages, including text, photos, and metadata, is extracted.
- Storing
The collected data is saved in a database or an index for simple retrieval, additional research, and analysis.
- Following Links
The crawler website continues to follow links discovered on the current web page, repeating the fetching, parsing, and storing operation for each new URL.
- Rate Limiting
To avoid overloading websites, crawlers follow robots.txt directives and add pauses between requests.
To grasp more clearly how it works, I advise you to watch a video about how search works in the first place. Here’s a short video to help you comprehend its functioning principle:
4 Types of Web Crawlers
Web Crawler Search Engine
These use site crawlers to collect information for search engine results pages (SERPs) such as Bing and Google. They are geared for speed and efficiency and can manage large volumes of data over millions of web pages.
Focused
Also known as topical or vertical crawlers, these are designed to collect data from specific areas of interest or topics, such as news sites, academic papers, or industry-specific websites. They are optimized to identify and follow links related to their focus area, ignoring irrelevant content.
Incremental
This type focuses on updating already existing indexed data rather than fetching all the data from scratch. Incremental crawlers efficiently maintain up-to-date indexes by periodically revisiting and updating only the modified parts of websites.
Deep Web Crawler
These are designed to access and index content not readily available through a standard web crawler search engine, such as dynamic pages, databases, and content behind login forms. Deep web crawlers can navigate through forms, use credentials to access restricted areas, and parse JavaScript-generated dynamic content.
Cases of Use
I remember I first considered setting up a webcrawler browser when worked on SEO analysis, web archiving, and, a bit later on – security testing. But most of my colleagues employ it for…
- Market Research: For business purposes, you may employ web crawler technology to collect information about competitors, market trends, and client preferences.
- Price Comparison: If you run an e-commerce site, use crawlers to track competitors’ prices and change your own pricing strategy.
- Content Aggregation: News aggregators and content curation services apply crawlers to collect articles, blog entries, and other information from various sources.
- Academic Research: Feel free to collect data from online sources, databases, and forums, if need be.
- Search Engine Indexing: Crawlers assist search engines like Google in indexing web pages and provide relevant search results.
How to Build a Web Crawler

Well, to build a website crawler, you will need some coding skills. If you want to create a web crawler using a no-code approach, then I recommend a website crawling builder tool.
Let’s take this step-by-step.
- Set up your development environment.
- You start by choosing a language (for this tutorial, I am providing an example using Python.)
- Install libraries like requests for making HTTP requests, BeautifulSoup or lxml for parsing HTML, and Scrapy for a more comprehensive site spidering framework.

- Create the basic structure.
- Specify the URL(s) you want to crawl.
- For the basic structure, leverage the requests library to fetch the content of web pages by making HTTP requests.
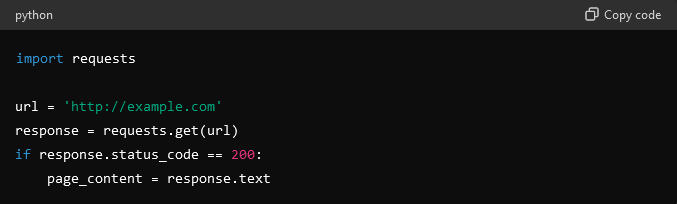
- Parse the HTML content.
- As soon as you have the content, move on to the next step, i.e., parse the HTML to extract the required information. You can use tools like BeautifulSoup or lxml for this task.
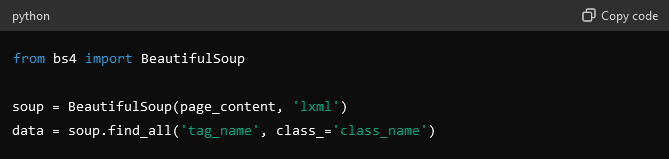
- Handle data extraction.
- In this step, you need to identify data points and determine what data you need, such as titles, links, or images.
- Now, extract data by using HTML tags and class names to locate and extract data.
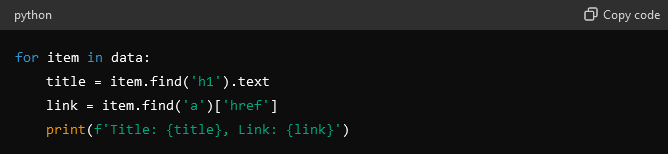
- Implement crawling logic.
- You will need to use recursive crawling and create functions to follow links and crawl additional pages.
- Identify and follow pagination links to continue site spidering seamlessly.
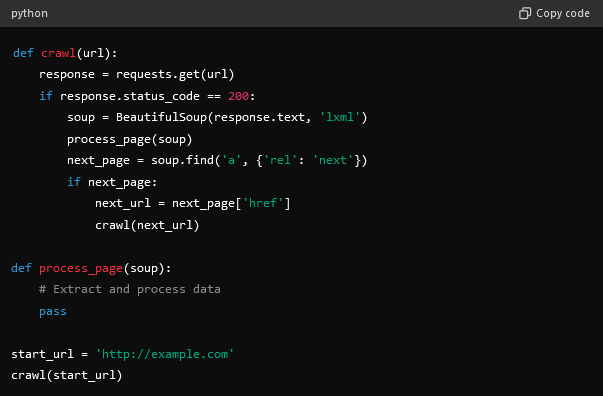
- Store the extracted data.
- Here, use a database like SQLite, MySQL, or MongoDB for structured storage.
- Once done, you must save data to CSV or JSON file format.
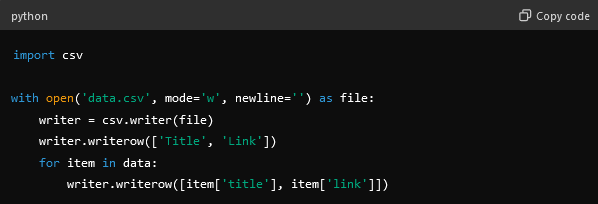
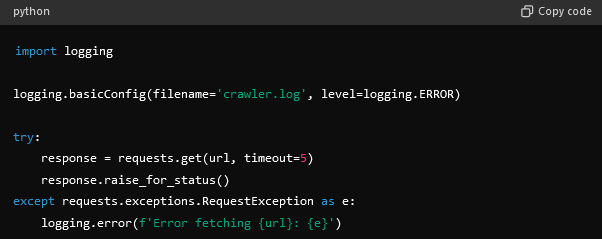
- Handle errors and exceptions.
- Set timeouts for HTTP requests to handle slow responses.
- Retry Failed Requests by implementing retry logic for failed requests.
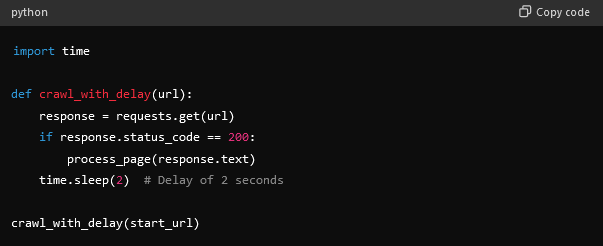
- Respect robots.txt and rate limiting.
- Ensure your crawler respects the robots.txt file of the target website.
- You can also utilize delays between requests to avoid overloading the server and affecting its performance.
Web Crawling vs. Web Scraping: What are the Differences?
And again, what is crawler? Website crawling entails regularly exploring the internet to index and discover web pages, generally for search engines. On the other hand, web scraping refers to obtaining specific data from websites for analysis and application in different fields like marketing, SEO, campaigns, etc.
| Aspect | Website Crawling | Web Scraping |
| Purpose | Indexing and discovering web pages | Extracting specific data from web pages |
| Use Case | Use cases for search engines (in the first place) to build or index the pages | Used by individuals and businesses to gather data for analysis |
| Process | A system that methodically follows links to discover new pages | Parses and extracts data from identified web pages |
| Tools | Googlebot, Bingbot, and other search engine bots | BeautifulSoup, Scrapy, Selenium |
| Output | A comprehensive index of web pages | CSV, JSON, or databases |
| Complexity | Generally more complex, it requires handling large-scale data | Can be simpler, but complexity increases with dynamic content |
How do Web Crawlers Affect SEO?
As I already said, web crawlers play an important part in search engine optimization (SEO) by indexing websites, which, in its turn, has a direct impact on how they appear in search results.
When a crawler explores a website, it evaluates the content, structure, and keywords to determine relevancy and rank. Effective SEO strategies, such as optimizing page speed, employing appropriate tags, and producing high-quality content, help crawlers efficiently index a site and, as a result, increase its visibility.
However, if you err and duplicate material, use broken links, or blocked resources, be ready that it might impede a crawler’s ability to index a site effectively, lowering the site’s search engine ranks.
Crawling Policies and Ethics
Crawling regulations and ethics are required to ensure the proper use of web crawlers. Websites frequently utilize robots.txt files to interact with crawlers, indicating which pages should not be crawled.
Ethical web crawling adheres to these rules, avoids overloading servers with excessive requests, and protects user privacy by avoiding collecting sensitive data without consent. Ignoring these standards might result in legal consequences and harm a website’s reputation.
I’d also add to ethical issues the gaining explicit consent, ensuring that the data obtained is used responsibly, and respecting both the website’s and users’ rights.
Future Trends
You all know about ML and AI, right? Well, to my mind, advances in artificial intelligence (AI) and machine learning (ML) will define the future of website crawling. I presume AI-powered crawlers will become more intelligent, able to recognize context, and extract more relevant information. Furthermore, I consider the rise of voice search and mobile-first indexing will affect how crawlers rank and index material.
Besides, the growing emphasis on user privacy and data security should compel the creation of spider crawlers that adhere to more demanding legislative frameworks, assuring ethical and responsible data collection activities.
Final Thoughts
Web crawler technology is critical to the digital ecosystem, influencing SEO, market research, and content aggregation. To prevent legal concerns and assure responsible data acquisition, I highly recommend you follow ethical crawling procedures and obey crawling policies. And be ready for future AI and machine learning breakthroughs to make web crawlers more efficient and context-aware.
FAQ
The meaning says it’s the process by which automated programs systematically browse the internet to index content from websites, gather data to update search engine indexes, and enable efficient retrieval of information when you perform searches.
They browse the web, fetching and parsing HTML to collect and index data from web pages to gather the information for different purposes.
Crawlers index web pages, enabling search engines to deliver users relevant and up-to-date search results.
No, they vary in algorithms, scope, and focus depending on their specific goals and implementations.
Free web crawlers face challenges like rate limiting, CAPTCHAs, dynamic content, and compliance with robots.txt files.
They impact SEO by indexing site content, which affects visibility and ranking in search engine results pages.
No, web crawlers are restricted by robots.txt files and can be blocked from accessing certain parts of a website.
The main difference between crawling and scraping is that crawling indexes entire pages while scraping extracts specific data from specific sites.
Websites use robots.txt files and meta tags to specify which pages spidey crawlers can access and how frequently they can crawl.