Exploring Key Web Scraping Techniques: Your Practical Handbook

In the digital age, information reigns supreme, and the World Wide Web serves as a vast repository of data covering virtually every aspect of human knowledge. However, accessing and harnessing this wealth of information for analysis, research, or application requires more than just a simple search. That is where web scraping emerges as an invaluable tool…
Web Scraping: Definition & Purpose
No verbal overdoses here! It’s a technique that enables computers to sift through the HTML structure of web pages, mimicking human browsing but with unmatched speed and precision.
Imagine collecting product prices from various online stores for market analysis, tracking real-time stock prices, or gathering research data from multiple sources. Manually copying and pasting this information would be arduous and time-consuming. Web scraping means automating the data extraction process and allowing you to retrieve large volumes of data in a fraction of the time it would take manually.
However, as with any powerful tool, ethical considerations must be pinpointed! Website owners may have terms of use prohibiting scraping their content, and excessive or aggressive scraping can strain server resources. Responsible and respectful scraping practices involve
- Adhering to a website’s terms of use
- Using appropriate scraping intervals
- And avoiding overloading servers.
Techniques Time!
The informational riches of the World Wide Web await! Here are the top 8 scraping techniques for beginners and advanced digital wanderers.
#1 — Human Copy-and-Paste Web Scraping: Unveiling the Primal Technique
In this digital age of automation, it might seem paradoxical that such a method still holds relevance. Still, there are scenarios where the human touch triumphs over even the most advanced scraping technologies.
Imagine encountering a website with formidable defenses against automated scraping tools, employing CAPTCHAs, intricate anti-bot mechanisms, and rate-limiting tactics. In such cases, the digital barriers can render conventional data scraping tools ineffective.
So, this technique entails a human user manually navigating through a website, identifying the desired information, and copying it into a text file or spreadsheet. While it might appear rudimentary, it’s a strategic approach when automation is explicitly prohibited or thwarted.
Manual copy-and-paste scraping has its limitations, chief among them being its time-consuming and labor-intensive nature. Extracting substantial datasets via this method can become a formidable task, demanding patience and meticulous attention to detail. Moreover, the potential for human error looms large, as fatigue and distraction can inadvertently introduce inaccuracies into the gathered data.
Despite these drawbacks, manual copy-and-paste scraping can find its niche utility, particularly for small businesses or projects with limited data requirements!
Need to scrape specific social media? Read these posts!
#2 — Text Pattern Matching: Harnessing Simplicity for Web Data Extraction
In the intricate tapestry of data scraping techniques, one approach stands out for its elegant simplicity and remarkable versatility: text pattern matching. This method harnesses the power of textual patterns, employing tools like the UNIX grep command or regular expression-matching capabilities of programming languages like Perl or Python. While it might seem straightforward, its effectiveness in extracting valuable information from web pages is anything but ordinary!
At its core, text pattern matching involves identifying specific sequences of characters or strings within a web page’s HTML source code. These sequences, often called patterns, act as virtual signposts that guide the extraction process. Web scrapers can precisely locate and capture relevant information, product prices, contact details, and even textual insights by defining the patterns that encapsulate the desired data.
Key advantages of text pattern matching are…
- Precision: Text pattern matching allows for surgical precision in data extraction. Scrapers can target specific data points by defining precise patterns without capturing extraneous content.
- Adaptability: Regular expressions, a fundamental tool in text pattern matching, enable dynamic pattern definitions. This adaptability proves invaluable when web page structures evolve.
- Versatility: This method isn’t limited to a specific programming language or platform. Whether it’s the familiar grep command or a popular language’s robust regular expression libraries, this option remains a cross-compatible technique.
- Speed: For tasks involving relatively simple pattern matching, the speed of execution is commendable. It offers a quick solution for scenarios where extensive parsing is optional.
- Customization: As data requirements vary, pattern definitions can be customized to fit specific needs. This versatility ensures that even complex extraction tasks can be accomplished using this approach.
However, it’s important to tread with caution! While text pattern matching excels in many cases, its reliance on predefined patterns can falter if the website’s structure undergoes significant changes. Additionally, over-reliance on regular expressions might lead to complex and hard-to-maintain code.
#3 — HTTP Programming: Unlocking Web Content Through Socket Magic
This method involves crafting HTTP requests and establishing connections to remote web servers using socket programming. Through this process, the doors to a treasure trove of digital information swing open, enabling scrapers to navigate the World Wide Web’s complex landscape.
In the case of static information, where content remains unchanged over time, HTTP programming allows scrapers to send simple GET requests to retrieve the HTML source code directly. This source code is the essence of the page’s content and is ripe for parsing and data extraction.
However, the true prowess of HTTP programming shines when dealing with dynamic information. Unlike their static counterparts, these pages are generated on-the-fly, often through JavaScript and other client-side technologies. Here, scrapers craft POST requests that encapsulate the necessary parameters and mimic user interactions. By sending these tailored requests, scrapers elicit dynamic responses from the server, effectively unlocking the concealed content. Great success!
This technique’s strength lies in its versatility. It adapts to various programming languages and platforms, offering scrapers the flexibility to choose tools that align with their expertise. Nonetheless, a caveat exists: dynamic web pages are prone to changes, and maintaining robust scrapers requires vigilance in monitoring updates.
#4 & 5 — Parsing techniques
👉 HTML Parsing: Decoding the Web’s Structured Tapestry
The technique of HTML parsing emerges as a key to unlocking the treasures hidden within dynamic web pages. Many websites curate vast collections of pages, often generated on-the-fly from structured sources like databases. While visually diverse, these pages often adhere to a common script or template underlying their content presentation. HTML parsing dives deep into this structured tapestry, allowing scrapers to discern patterns, extract information, and convert it into a relational form.
At the heart of HTML parsing is a “wrapper.” This ingenious program detects recurring templates within a particular information source, captures their content, and transforms it into a format that mirrors a database’s relational structure. The algorithms orchestrating wrapper generation assume a shared template among input pages, relying on a consistent URL scheme for identification.
But HTML parsing’s utility extends further! Semi-structured data query languages (for instance, XQuery and HTQL) come into play to traverse the intricacies of HTML pages. These languages enable scrapers to parse the pages and retrieve, transform, and mold the content to their requirements.
Yet, challenges abound (well, of course). Websites’ structures can evolve, leading to shifts that require vigilant updates to scraping scripts. The precision required in identifying templates also demands a meticulous approach to crafting wrappers. The balance between complexity, simplicity, adaptability, and rigidity is a dance web scrapers must master.
👉 DOM Parsing: Navigating the Web’s Dynamic Labyrinth
By integrating complete web browsers like Internet Explorer or Mozilla browser controls, programs delve into the heart of the web, retrieving and interacting with content generated in real time by client-side scripts.
The beauty of DOM parsing lies in its ability to convert web pages into Document Object Model (DOM) trees. Like this one!
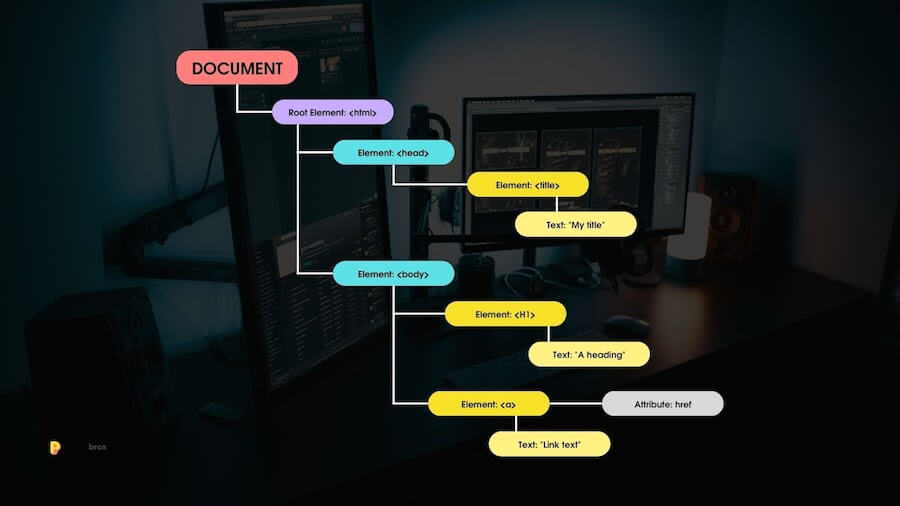
These trees represent the hierarchical structure of a web page’s elements, from headings and paragraphs to images and links. Through this tree-based representation, scrapers gain the power to pinpoint and extract specific parts of a page’s content.
To navigate the DOM tree effectively, languages like XPath come into play. XPath provides a concise way to traverse and query elements within the DOM, facilitating seamless data extraction. This approach empowers scrapers to target data embedded within complex page structures precisely.
While DOM parsing offers unparalleled insights into dynamic content, it also demands a nuanced approach. Browser control integration adds complexity, and the reliance on browser capabilities may slow down the scraping process. Furthermore, as web technologies evolve, compatibility becomes a consideration that requires continuous attention.
#6 — Semantic Annotation Recognition: Unveiling the Web’s Hidden Gems
Many pages embrace metadata or semantic markups and annotations that provide structured information about the data they present. Semantic annotation recognition harnesses these cues to navigate and extract specific data snippets rapidly.
Web pages enriched with annotations, such as those in Microformat, offer scrapers an opportunity to delve into a realm where data is subtly organized within the page’s structure. That can be likened to a specialized form of DOM parsing, where semantic cues guide the scraper to target desired content accurately.
Alternatively, semantic annotations can be organized into a separate “semantic layer,” detached from the web pages. This layer acts as a repository of data schema and instructions. With knowledge from this layer, Scrapers can intelligently navigate web pages, understanding their structure and discerning where valuable data lies.
However, this technique is rather complex… Adhering to various annotation standards and navigating potential inconsistencies can be demanding. Additionally, annotations provide valuable insights but might only sometimes encompass the full breadth of data that scrapers seek.
#7 — Vertical Aggregation: Elevating Web Harvesting Precision
Unlike traditional scraping methods that involve crafting specific scrapers for individual target sites, vertical aggregation focuses on creating a comprehensive knowledge base for an entire industry. A platform can employ this to generate and deploy specialized bots autonomously. This innovative approach eliminates the need for constant human oversight, streamlining the process and ensuring up-to-date data retrieval.
Vertical aggregation’s strength lies in delivering highly relevant and specific information. By focusing on the nuances of a particular vertical, these platforms optimize data extraction for accuracy and efficiency. However, challenges persist in maintaining data quality, adapting to evolving website structures, and navigating ethical considerations to ensure compliance with terms of use.
#8 — Computer Vision Webpage Analysis: Seeing the Web through AI Eyes
In the quest for innovative data scraping techniques, computer vision webpage analysis emerges as a groundbreaking approach that mimics human perception through the lens of artificial intelligence (AI). Efforts in this domain leverage machine learning and computer vision to interpret information visually, akin to how a human would perceive and comprehend them.
By harnessing advanced AI algorithms, computer vision-based scraping seeks to recognize and extract information by comprehending the visual elements of web pages. This method involves training models to discern text, images, layouts, and other visual cues comprising the webpage’s structure.
Through this approach, web pages are not merely treated as collections of text and code but as dynamic visual compositions. As technology advances, machine learning models become increasingly adept at deciphering intricate layouts and patterns, enabling accurate data extraction. (I find this particularly cool)
However, the complexity of visual analysis brings challenges. Variability in page designs, font styles, and image formats can pose hurdles for accurate interpretation. Despite these challenges, the promise of computer vision webpage analysis lies in its potential to provide a holistic understanding of web content, bridging the gap between human perception and machine intelligence.
The Legality of Web Scraping: Navigating the Legal Landscape
PLEASE NOTE!!!
Web scraping legality varies across jurisdictions, with factors like data privacy, copyright, and terms of use playing crucial roles. Here’s a glimpse of the legal stance in different regions:
📜 United States:
- Web scraping may infringe copyright if data is protected.
- Violating a website’s terms of use could lead to legal action.
- The Computer Fraud & Abuse Act (abbreviated: CFAA) applies if unauthorized access occurs.
📜 European Union (EU):
- The General Data Protection Regulation (abbreviated: GDPR) mandates data protection and user consent.
- Scraping personal data without consent can result in hefty fines.
📜 Australia:
- The Copyright Act may apply to scraping content, especially if an original expression is copied.
- Website terms of use violations could lead to legal action.
📜 India:
- The Information Technology Act governs unauthorized access and data breaches.
- Violating a website’s terms of use could result in legal action.
Actions against web scrapers can range from legal notices and cease-and-desist orders to fines and lawsuits. It’s crucial to understand the legal environment in the specific jurisdiction and adhere to ethical scraping practices to avoid legal complications! Please do not neglect that!!
Conclusion: Navigating the Web’s Data Seas
In the intricate realm of data scraping, diverse techniques offer avenues to glean insights from the digital landscape. From humble copy-and-paste methods to AI-powered computer vision, each approach carries its strengths and intricacies.
While legality and ethical considerations underscore these endeavors, the world of web scraping continues to evolve, driven by a quest for knowledge and innovation.
Best of luck with your next scraping session! And stay safe in the digital realm.